
Wyrażenia regularne, znane też jako regex (albo regexp), to naprawdę potężne narzędzie, które pozwala opisywać i dopasowywać wzorce w tekście. Są one niezwykle przydatne w programowaniu, analizie danych czy administracji systemami, dając Ci kontrolę nad tym, jak precyzyjne i elastycznie możesz manipulować ciągami znaków. Ten artykuł jest dla każdego, kto chce po prostu zrozumieć, czym te wyrażenia są, jak działają i gdzie można je wykorzystać. Przejdziemy od ich historycznych korzeni, przez praktyczne przykłady, aż po typowe błędy – po prostu zanurzymy się w fascynujący świat regex.
Czym właściwie są wyrażenia regularne? Garść historii i definicji
Wyrażenia regularne to po prostu specjalne sekwencje znaków, które tworzą pewien wzorzec. Ten wzorzec potem wykorzystujemy do wyszukiwania lub dopasowywania konkretnych kombinacji znaków w większym kawałku tekstu. Można to też ująć tak: regex to taki swój własny język do definiowania wzorców tekstowych, który pozwala na naprawdę skomplikowane operacje wyszukiwania, walidacji czy zamiany tekstu. Cały ten koncept został formalnie opisany przez matematyka Stephena Cole Kleene’a już w latach 50. XX wieku. Ale na szerszą skalę zaczęto je stosować od 1968 roku, głównie w kontekście edycji tekstu i narzędzi dla programistów. Dzisiaj mamy różne standardy i „dialekty” regex, takie jak POSIX czy PCRE (czyli Perl Compatible Regular Expressions), które wpływają na dokładną składnię i dostępne funkcje. Zrozumienie tych podstaw to klucz do efektywnego ich używania.
Podstawowe klocki składni wyrażeń regularnych
Żeby zacząć tworzyć własne, skuteczne wyrażenia regularne, musisz poznać ich podstawowe elementy. Składnia regex opiera się na połączeniu zwykłych znaków, które oznaczają same siebie, z tzw. metaznakami, które mają specjalne znaczenie i zmieniają sposób dopasowywania. Dzięki metaznakom możesz tworzyć złożone reguły, które pozwalają na znacznie więcej niż zwykłe wyszukiwanie tekstu. Zrozumienie tych podstaw jest absolutnie niezbędne, nawet jeśli chcesz tworzyć tylko proste wyrażenia.
Znaki specjalne (metaznaki) i co one robią
Metaznaki to tak naprawdę serce składni wyrażeń regularnych, to one dają im tę całą moc i elastyczność. Każdy z nich ma swoje konkretne zadanie w definiowaniu wzorca:
- Kropka (.): Reprezentuje dowolny pojedynczy znak, z wyjątkiem znaku nowej linii. To taki podstawowy „dziki kart” w regex.
- Karetka (^): Działa jak kotwica, która dopasowuje początek ciągu znaków lub linii.
- Dolar ($): Też jest kotwicą, dopasowującą koniec ciągu znaków lub linii.
- Gwiazdka (*): To kwantyfikator oznaczający „zero lub więcej” wystąpień poprzedzającego elementu. Może to być znak, klasa znaków lub grupa.
- Plus (+): Kolejny kwantyfikator, który oznacza „jedno lub więcej” wystąpień poprzedzającego elementu. Czyli musi być co najmniej jedno dopasowanie.
- Znak zapytania (?): Może mieć dwojakie znaczenie: jako kwantyfikator oznacza „zero lub jedno” wystąpienie (czyli element jest opcjonalny), albo jako modyfikator zmienia zachowanie innego kwantyfikatora z „zachłannego” na „leniwy”.
- Klamry ({n,m}): Pozwalają precyzyjnie określić zakres powtórzeń poprzedzającego elementu – od n do m razy. Są też warianty {n} (dokładnie n razy) i {n,} (co najmniej n razy).
- Nawiasy kwadratowe ([]): Definiują klasę znaków, dopasowując dowolny pojedynczy znak, który znajduje się wewnątrz nawiasów. Można tu umieścić pojedyncze znaki, zakresy (np. a-z) lub ich kombinacje.
- Nawiasy okrągłe (()): Służą do grupowania podwyrażeń. Dzięki nim można zastosować kwantyfikatory do całej grupy znaków albo „przechwycić” dopasowany fragment tekstu do późniejszego wykorzystania.
- Kreska pionowa (|): Działa jak operator „lub”, pozwalając zdefiniować alternatywne wzorce. Dopasuje się do tego fragmentu tekstu, który pasuje do jednej z podanych opcji.
- Backslash (\): To znak „ucieczki” (escape). Służy do dwóch celów: po pierwsze, żeby zneutralizować specjalne znaczenie metaznaku (np. \. dopasuje dosłowną kropkę, a nie dowolny znak), po drugie, żeby zdefiniować specjalne sekwencje znaków.
Sekwencje specjalne – skróty, które ułatwiają życie
Oprócz standardowych metaznaków, mamy też predefiniowane sekwencje specjalne, które are skrótami dla często używanych klas znaków:
- \d: Dopasowuje dowolną cyfrę ([0-9]).
- \D: Dopasowuje dowolny znak, który nie jest cyfrą (to negacja \d).
- \w: Dopasowuje dowolny „znak słowny”, który zazwyczaj obejmuje litery (a-z, A-Z), cyfry (0-9) oraz znak podkreślnika (_).
- \W: Dopasowuje dowolny znak, który nie jest znakiem słownym (to negacja \w).
Te elementy składni pozwalają tworzyć naprawdę precyzyjne i elastyczne wzorce tekstowe, które znajdują zastosowanie w wielu obszarach informatyki.
Gdzie wyrażenia regularne mają największe zastosowanie?
Wyrażenia regularne przydają się praktycznie w każdym zakątku IT, gdzie trzeba cokolwiek zrobić z tekstem. Ich siła polega na tym, że można za ich pomocą zdefiniować skomplikowane reguły wyszukiwania i manipulacji danymi tekstowymi, co jest nieosiągalne za pomocą prostego wyszukiwania. Regex to nieocenione narzędzie dla programistów, administratorów, analityków danych, a nawet specjalistów od SEO.
- Wyszukiwanie i Dopasowywanie: To absolutna podstawa używania regex. Pozwalają one na znalezienie konkretnych wzorców w ogromnych blokach tekstu, co jest super przydatne przy parsowaniu logów, szukaniu informacji w bazach danych czy analizie treści. Wyobraź sobie, że chcesz znaleźć wszystkie adresy e-mail w dokumencie – z regexem, używając wzorca takiego jak ([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5}), zrobisz to bez problemu.
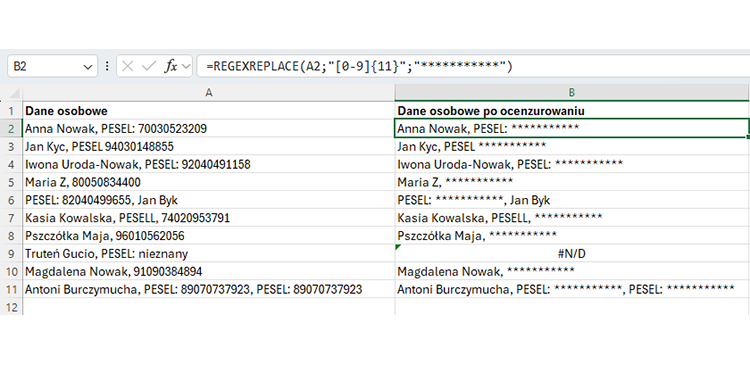
- Walidacja Danych: Regex są bardzo często używane do sprawdzania, czy dane wprowadzane przez użytkowników w formularzach internetowych, aplikacjach mobilnych czy systemach rejestracji są poprawne. Można nimi weryfikować format numeru telefonu, adresu e-mail, kodu pocztowego, numeru PESEL, a nawet złożone wymagania dotyczące haseł, upewniając się, że spełniają one określone kryteria bezpieczeństwa.
- Zastępowanie i Ekstrakcja: Regex umożliwiają nie tylko znajdowanie, ale też modyfikowanie tekstu. Funkcje zastępowania pozwalają na zamianę znalezionych wzorców na inne ciągi znaków – to przydatne przy czyszczeniu danych, anonimizacji informacji czy formatowaniu tekstu. Z kolei ekstrakcja danych pozwala wyciągnąć konkretne fragmenty tekstu pasujące do wzorca, na przykład numery telefonów z nieustrukturyzowanego tekstu.
- Przetwarzanie Tekstu i Logów: W systemach operacyjnych typu Unix/Linux, narzędzia takie jak grep, sed, awk powszechnie korzystają z wyrażeń regularnych, żeby efektywnie przeszukiwać i manipulować plikami tekstowymi, w tym plikami logów serwerowych. Dzięki temu można szybko znaleźć błędy, analizować ruch sieciowy czy monitorować wydajność systemu.
- Użycie w Językach Programowania: Praktycznie każdy współczesny język programowania oferuje wsparcie dla wyrażeń regularnych. W Pythonie jest to moduł re, w JavaScript mamy metody obiektów stringowych i obiekt RegExp, a w Javie klasy Pattern i Matcher. Obsługa regex jest też obecna w frameworkach i językach takich jak .NET, PHP czy Perl, co czyni je uniwersalnym narzędziem dla programistów.
- SEO i Marketing Cyfrowy: Wyrażenia regularne znajdują swoje miejsce w narzędziach analitycznych, takich jak Google Analytics czy Google Tag Manager. Pozwalają one na tworzenie niestandardowych dopasowań filtrów, grup treści czy celów, co umożliwia bardziej precyzyjną analizę ruchu na stronie i zachowań użytkowników.
Jak nauczyć się wyrażeń regularnych? Kilka inspiracji
Nauka wyrażeń regularnych może na początku wydawać się trochę zniechęcająca, głównie ze względu na specyficzną składnię i mnogość metaznaków. Pero kluczem do sukcesu jest systematyczne podejście i regularne ćwiczenia. Na szczęście jest mnóstwo zasobów, które pomagają w tym procesie – od interaktywnych narzędzi po obszerne poradniki.
Interaktywne narzędzia i kursy online – nauka przez działanie
Najlepszym sposobem na naukę regex jest po prostu ich używanie w praktyce. Interaktywne platformy oferują środowisko, w którym od razu możesz testować swoje wzorce i widzieć efekty:
- RegexLearn: To świetne miejsce na start. Platforma oferuje interaktywny kurs krok po kroku, piaskownicę do testowania wyrażeń i różne ćwiczenia dopasowane do Twojego poziomu.
- regex101.com: Bardzo popularne narzędzie online, które działa jak interaktywna konsola dla wyrażeń regularnych. Wpisujesz wzorzec i tekst, a ono od razu podświetla dopasowane fragmenty i wyjaśnia działanie poszczególnych elementów regex.
- RegEx – Wyrażenia Regularne od A do Z (eduj.pl): To kompleksowy kurs online, który przeprowadzi Cię przez wszystkie aspekty wyrażeń regularnych, od podstaw po zaawansowane techniki, z naciskiem na praktyczne zastosowania w walidacji, wyszukiwaniu i zamianie tekstu.
Samouczki i poradniki – teoria z przykładami
Oprócz interaktywnych narzędzi, warto sięgnąć po materiały teoretyczne, które wyjaśnią Ci wszystko krok po kroku i podadzą przykłady:
- Bulldogjob: Znajdziesz tu przystępny samouczek, który krok po kroku wprowadza w świat regex, pokazując, jak efektywnie wyciągać informacje z tekstu.
- Mirosław Mamczur: Na tej stronie jest podstawowe wprowadzenie do wyrażeń regularnych, wyjaśniające kluczowe elementy składni, takie jak metaznaki, kwantyfikatory i grupowanie.
- Semcore: Udostępnia poradnik skupiający się na praktycznych zastosowaniach regex w kontekście SEO, co może być ciekawe dla osób pracujących w marketingu cyfrowym.
Dokumentacja techniczna i książki – dla tych, co chcą wiedzieć więcej
Jeśli chcesz głębiej zrozumieć temat i odnieść się do konkretnych implementacji, warto zajrzeć do oficjalnej dokumentacji i publikacji:
- Microsoft Learn: Dokumentacja Microsoftu zawiera szczegółowe przewodniki dotyczące wyrażeń regularnych w środowisku .NET, bogate w przykłady kodu i tabele interpretacji znaków specjalnych.
- Książka Michaela Fitzgeralda „Wyrażenia regularne. Wprowadzenie”: To kompleksowy podręcznik, który obejmuje zagadnienia od podstawowych po zaawansowane techniki wyszukiwania i zastępowania, z naciskiem na implementację w języku Perl.
Jak się uczyć skutecznie? Kilka wskazówek
Żeby nauka faktycznie przyniosła efekty, warto trzymać się kilku prostych zasad:
- Zacznij od prostych rzeczy: Nie rzucaj się od razu na głęboką wodę ze skomplikowanymi wzorcami. Zacznij od dopasowania pojedynczych znaków, potem sekwencji, a dopiero potem dodawaj kwantyfikatory i alternatywy.
- Testuj każdy dodany element: Po dodaniu nowego metaznaku lub sekwencji, od razu przetestuj jej działanie w interaktywnym narzędziu. Tylko tak naprawdę zrozumiesz, jak to wpływa na dopasowanie.
- Analizuj przykłady: Przeglądaj gotowe wyrażenia regularne i próbuj zrozumieć, dlaczego one działają właśnie tak, a nie inaczej. To świetny sposób na poznanie nowych, sprytnych technik.
- Dokumentuj to, co tworzysz: Kiedy tworzysz jakieś skomplikowane wyrażenie, dodaj komentarze wyjaśniające, co robią poszczególne jego części. Ułatwi to zrozumienie Tobie i innym w przyszłości.
Błędy w pisaniu wyrażeń regularnych – czego unikać?
Pomimo całej swojej mocy, wyrażenia regularne są dość podatne na błędy, które mogą prowadzić do nieprawidłowego działania kodu, problemów z wydajnością, a nawet luk bezpieczeństwa. Wiedza o najczęstszych pułapkach i sposobach ich unikania jest kluczowa dla każdego, kto pracuje z regex.
- Zbyt Skomplikowane Wzorce: Częstym błędem jest tworzenie zbyt złożonych, trudnych do odczytania i utrzymania wyrażeń regularnych. Zamiast tego powinieneś dążyć do prostoty, budować wzorce stopniowo i je dokumentować, żeby były zrozumiałe.
- Problemy z Grupami Przechwytującymi: Niewłaściwe użycie nawiasów okrągłych () do grupowania i przechwytywania może prowadzić do błędów. Jeśli grupa nie jest potrzebna do przechwycenia, użyj nieprzechwytujących grup (?:…), aby uniknąć niepotrzebnego obciążenia i ułatwić odczytanie wyników.
- Błędy z Ucieczkami (Backslash): W wielu językach programowania, jak Python czy JavaScript, specjalne znaki w wyrażeniach regularnych (np. \, . , *) muszą być dodatkowo „uciekane” za pomocą kolejnego backslasha wewnątrz literału stringa. Prowadzi to do sytuacji, gdzie w kodzie pojawia się \\d zamiast \d. Rozwiązaniem jest stosowanie surowych stringów (raw strings), gdzie backslash nie jest interpretowany jako znak specjalny języka programowania.
- Zachłanne Powtórzenia (Greedy Matching): Domyślnie kwantyfikatory (*, +, {n,m}) są „zachłanne”, co oznacza, że próbują dopasować jak najdłuższy możliwy fragment tekstu. Może to prowadzić do nieoczekiwanych wyników, np. dopasowania całego pliku zamiast pojedynczej linii. Aby temu zaradzić, używaj leniwych wersji kwantyfikatorów, dodając znak zapytania (*?, +?, {n,m}?), które minimalizują dopasowanie.
- Ignorowanie Flag i Modyfikatorów: Często zapominamy o flagach takich jak i (ignorowanie wielkości liter) czy g (dopasowanie globalne). Brak ich użycia może spowodować, że wyrażenie nie zadziała zgodnie z oczekiwaniami w różnych scenariuszach. Zawsze warto sprawdzić dostępne flagi dla danego silnika regex.
- Brak Testowania i Walidacji: Największym błędem jest poleganie na „intuicji” i nieprzetestowanie wyrażeń regularnych na różnorodnych danych, w tym przypadkach brzegowych. Źle napisane regex mogą prowadzić do ataków typu Denial-of-Service (DoS) poprzez tzw. „catastrophic backtracking”, czyli nadmierne obciążenie procesora. Zawsze używaj narzędzi online do testowania i walidacji, a w krytycznych aplikacjach stosuj limity czasowe na wykonanie operacji regex.
- Inne pułapki: Uważaj na prawidłowe stosowanie kwantyfikatorów, różnice między silnikami regex (np. BRE, ERE, PCRE) oraz prawidłową obsługę znaków spoza zakresu ASCII, korzystając z flag dla Unicode, gdzie jest to potrzebne.
Podsumowanie: potęga i przyszłość wyrażeń regularnych
Wyrażenia regularne, czyli regex, to niezwykle potężne narzędzie do pracy z tekstem, które oferuje elastyczność i precyzję, której nie da się osiągnąć za pomocą prostego wyszukiwania znaków. Ich składnia, oparta na kombinacji znaków zwyczajnych i metaznaków, pozwala tworzyć złożone wzorce do wyszukiwania, walidacji, ekstrakcji i transformacji danych tekstowych. Mimo długiej historii, regex pozostają niezastąpione w wielu dziedzinach IT, od tworzenia oprogramowania i analizy danych, po administrację systemami i SEO. W erze uczenia maszynowego i NLP (Natural Language Processing), regex wciąż odgrywają ważną rolę, często służąc jako narzędzie do preprocessingu danych przed przekazaniem ich do bardziej zaawansowanych modeli. Opanowanie wyrażeń regularnych to więc cenna inwestycja w rozwój umiejętności każdego specjalisty pracującego z tekstem i danymi.
FAQ – najczęściej zadawane pytania o wyrażenia regularne
Czym różni się regex od zwykłego wyszukiwania tekstu?
Odpowiedź: Zwykłe wyszukiwanie tekstu (jak np. Ctrl+F w edytorze) szuka dokładnie takiego samego ciągu znaków. Wyrażenia regularne pozwalają na definiowanie wzorców, które mogą reprezentować całe klasy znaków, ich powtórzenia lub alternatywy, co daje znacznie większą elastyczność i precyzję w znajdowaniu dopasowań.
Czy wyrażenia regularne są trudne do nauczenia?
Odpowiedź: Opanowanie wyrażeń regularnych wymaga czasu i praktyki, zwłaszcza na początku ze względu na specyficzną składnię. Jednak dzięki dostępnym zasobom, takim jak interaktywne narzędzia online i kursy, można je skutecznie opanować poprzez systematyczne ćwiczenia i stopniowe budowanie wiedzy.
W jakich językach programowania regex są najczęściej używane?
Odpowiedź: Wyrażenia regularne są powszechnie dostępne i wykorzystywane we wszystkich popularnych językach programowania. Należą do nich między innymi Python (biblioteka re), JavaScript (wbudowane metody stringów i obiekt RegExp), Java (klasy Pattern i Matcher), C# (klasa Regex), PHP oraz Perl.
Czy istnieją narzędzia, które pomagają w pisaniu regex?
Odpowiedź: Tak, istnieje wiele doskonałych interaktywnych narzędzi online, które znacząco ułatwiają tworzenie i testowanie wyrażeń regularnych. Do najpopularniejszych należą regex101.com, regexr.com oraz RegexLearn, które oferują podgląd dopasowań w czasie rzeczywistym, podpowiedzi składniowe i wyjaśnienia.
Czy wyrażenia regularne mogą być niebezpieczne?
Odpowiedź: Tak, nieprawidłowo napisane lub celowo złośliwie skonstruowane wyrażenia regularne mogą stanowić zagrożenie bezpieczeństwa. Mogą one prowadzić do ataków typu Denial-of-Service (DoS) poprzez nadmierne obciążenie procesora komputera (tzw. „catastrophic backtracking”). Dlatego kluczowe jest stosowanie ich z rozwagą, testowanie i implementowanie mechanizmów ograniczających czas wykonania operacji.


Poszukujesz agencji SEO w celu wypozycjonowania swojego serwisu? Skontaktujmy się!

Paweł Cengiel
Cechuję się holistycznym podejściem do SEO, tworzę i wdrażam kompleksowe strategie, które odpowiadają na konkretne potrzeby biznesowe. W pracy stawiam na SEO oparte na danych (Data-Driven SEO), jakość i odpowiedzialność. Największą satysfakcję daje mi dobrze wykonane zadanie i widoczny postęp – to jest mój „drive”.
Wykorzystuję narzędzia oparte na sztucznej inteligencji w procesie analizy, planowania i optymalizacji działań SEO. Z każdym dniem AI wspiera mnie w coraz większej liczbie wykonywanych czynności i tym samym zwiększa moją skuteczność.





