Zastanawiałeś się kiedyś, jak wiele rzeczy wpływa na coś jednego? Na przykład, co sprawia, że sprzedaż produktu idzie lepiej lub gorzej? Regresja wieloraka to właśnie narzędzie, które pozwala nam to rozgryźć. To metoda statystyczna, która pomaga nam zrozumieć i przewidzieć wartość jednej rzeczy (nazwijmy ją Y), patrząc na to, jak wpływa na nią kilka innych rzeczy (nazwijmy je X₁, X₂, aż do Xₚ). To taki rozbudowany kuzyn prostej regresji, gdzie analizujemy tylko jeden czynnik. Dzięki niej możemy ogarnąć te wszystkie złożone powiązania między zmiennymi, co jest nieocenione w nauce i biznesie.
Dlaczego warto znać regresję wieloraką w analizie danych?
Dzięki tej metodzie możemy nie tylko wskazać, ale też zmierzyć, jak wiele różnych czynników wpływa na to, co obserwujemy. To pozwala nam lepiej zrozumieć, co się dzieje i podejmować mądrzejsze decyzje. W tym artykule pokażę Ci, czym dokładnie jest regresja wieloraka, jak działa jej model, gdzie można ją zastosować i na co uważać, żeby się nie pogubić.
Jak działa model regresji wielorakiej?
Wyobraź sobie, że chcesz dopasować prostą linię do punktów na wykresie. Model regresji wielorakiej robi coś podobnego, tylko że szuka funkcji (najczęściej liniowej), która najlepiej opisuje, jak jedna zmienna zależy od wielu innych. Celem jest, żeby błędy w przewidywaniach były jak najmniejsze.
Jaka jest ogólna postać modelu regresji wielorakiej?
Najprościej mówiąc, taki model wygląda tak: Y = a + b₁X₁ + b₂X₂ + … + bₚXₚ.
- Y – to właśnie ta zmienna, którą chcemy wyjaśnić albo przewidzieć.
- Xᵢ – to nasze zmienne niezależne, czyli te czynniki, które według nas wpływają na Y.
- a – to stała, nasz punkt startowy. Pokazuje, ile wynosiłoby Y, gdyby wszystkie X były równe zero.
- bᵢ – to nasze współczynniki regresji. Mówią nam, jak mocno i w którą stronę Xᵢ wpływa na Y, pod warunkiem, że inne czynniki się nie zmieniają.
Do szacowania tych współczynników często używa się metody najmniejszych kwadratów. Chodzi w niej o to, żeby suma kwadratów różnic między tym, co faktycznie zaobserwowaliśmy, a tym, co przewidział model, była jak najmniejsza. Zrozumienie tych współczynników jest kluczowe. Ich znak – plus albo minus – mówi nam o kierunku zależności, a wielkość o jej sile.
Jakie są kluczowe założenia modelu regresji wielorakiej?
Żeby wyniki analizy regresji wielorakiej były wiarygodne, musimy pamiętać o kilku ważnych założeniach. Jeśli je zignorujemy, możemy dojść do błędnych wniosków.
- Liniowość: Zakładamy, że zależność między zmienną zależną a każdą ze zmiennych niezależnych jest prosta – jak linia. Czyli zmiana o jedną jednostkę w X powoduje stałą zmianę w Y.
- Normalność reszt: Różnice między tym, co faktycznie wyszło, a tym, co przewidział model (czyli reszty), powinny mieć rozkład normalny. Mówiąc prościej, błędy naszego modelu powinny być losowe i równo rozłożone wokół zera.
- Brak obserwacji odstających: Nie powinno być w danych takich punktów, które mocno odstają od reszty i mogłyby zaburzyć nasze wyniki.
- Homoscedastyczność: To znaczy, że wariancja błędów powinna być taka sama na wszystkich poziomach zmiennych niezależnych. Nasz model powinien być równie dobry w przewidywaniu w całym zakresie danych.
- Niezależność zmiennych niezależnych (brak multicollinearity): Nasze zmienne X nie powinny być ze sobą mocno skorelowane. Jeśli są, trudno będzie nam jednoznacznie ocenić, jak każda z nich wpływa na Y.
- Odpowiednia wielkość próby: Musimy mieć wystarczająco dużo danych w stosunku do liczby zmiennych X, żeby model był stabilny i nie „przestawił się” tylko na nasze konkretne dane. Zwykle przyjmuje się, że potrzebujemy co najmniej 10-20 obserwacji na każdą zmienną X.
To, jak dobrze nasze dane spełniają te założenia, decyduje o wiarygodności modelu. Czasem, gdy coś nie gra, trzeba zmodyfikować dane lub wybrać inne metody analizy.
Kiedy stosować regresję wieloraką w praktyce?
Regresja wieloraka to naprawdę wszechstronne narzędzie. Znajdziemy ją w medycynie, ekonomii, psychologii, marketingu – praktycznie wszędzie tam, gdzie chcemy zrozumieć, jak wiele rzeczy wpływa na jeden wynik.
Główne obszary zastosowań regresji wielorakiej?
- Analiza wpływu czynników: To chyba najczęstsze zastosowanie. Chcemy wiedzieć, jak wydatki na reklamę, cena produktu i opinie klientów wpływają na sprzedaż.
- Zarządzanie personelem: Możemy ocenić, od czego zależy wysokość wynagrodzenia – czy od zakresu obowiązków, liczby podwładnych, czy może od stażu pracy. To pomaga wyłapać ewentualne nieprawidłowości w płacach.
- Analiza rentowności biznesowej: Badamy, jak koszty produkcji, wydatki na marketing czy promocje wpływają na zysk.
- Finanse: Sprawdzamy, jak różne wskaźniki finansowe wpływają na zysk netto firmy.
- Badania naukowe: Pomaga nam odkryć, które czynniki najlepiej opisują dane zjawisko i jakie są między nimi relacje, niezależnie od tego, czy badamy przyrodę, czy społeczeństwo.
- Redukcja złożoności danych: Czasem regresja wieloraka jest używana po to, żeby wyłowić te najważniejsze czynniki wpływające na wynik. Dzięki temu łatwiej nam zrozumieć skomplikowane dane. To naprawdę pomaga zobaczyć, co jest najważniejsze.
Jak interpretować wyniki i kluczowe statystyki regresji wielorakiej?
Żeby dobrze zrozumieć wyniki regresji wielorakiej, musimy przyjrzeć się kilku rzeczom: samemu równaniu, współczynnikom, miarom dopasowania modelu i analizie jego diagnostyki. Dopiero wtedy możemy wyciągnąć sensowne wnioski.
Jak interpretować równanie regresji i współczynniki?
Nasze równanie Y = a + b₁X₁ + b₂X₂ + … + bₚXₚ to serce modelu.
- a (wyraz wolny) mówi nam, jakie będzie Y, gdy wszystkie X będą równe zero.
- bᵢ (współczynniki) mówią, jak zmieni się Y, gdy zmienimy Xᵢ o jedną jednostkę, a reszta X pozostanie bez zmian. Znak plus czy minus pokaże kierunek, a wielkość – siłę wpływu.
Jeśli chcemy porównać wpływ różnych zmiennych X na Y, gdy mają one zupełnie inne skale, warto spojrzeć na współczynniki standaryzowane (oznaczane jako β). Mówią nam one o względnym znaczeniu każdego predyktora. Czy dany predyktor faktycznie ma wpływ na zmienną zależną, oceniamy po p-wartości. Jeśli jest niska (zwykle poniżej 0.05), możemy uznać, że wpływ jest statystycznie istotny.
Jakie są miary jakości dopasowania modelu?
Żeby ocenić, jak dobrze nasz model „pasuje” do danych, patrzymy na kilka wskaźników:
- Współczynnik determinacji R²: Pokazuje, jaki procent zmienności zmiennej zależnej (Y) tłumaczy nasz model. Im bliżej 1, tym lepiej. Czyli R² = 0.75 oznacza, że model wyjaśnia 75% tego, co się dzieje ze zmienną Y.
- Współczynnik korelacji wielorakiej R: To po prostu pierwiastek z R². Mierzy ogólną siłę związku między wszystkimi zmiennymi X razem a zmienną Y.
- Odchylenie standardowe reszt: Mówi nam, jak duży jest przeciętny błąd naszego modelu. Im mniejsza wartość, tym dokładniejsze są przewidywania.
- Kryteria informacyjne (np. AIC, BIC): Służą do porównywania różnych modeli. Niższa wartość zazwyczaj oznacza lepszy model, który dobrze dopasowuje dane, ale nie jest zbyt skomplikowany.
Jak analizować reszty i założenia modelu?
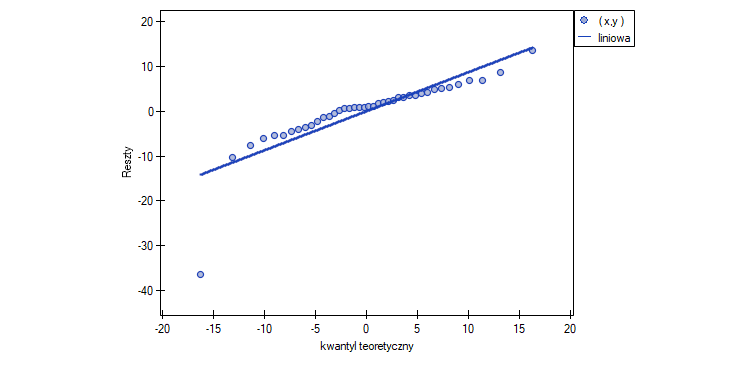
Analiza reszt jest jak „badanie” błędów naszego modelu. Reszty, czyli różnice między tym, co faktycznie zaobserwowaliśmy, a tym, co przewidział model, mogą nam wiele powiedzieć. Wykresy reszt pomagają nam zobaczyć, czy nie ma problemów z liniowością, czy wariancja błędów jest stała (homoscedastyczność) albo czy nie mamy obserwacji odstających.
Są też formalne testy, np. test Shapiro-Wilka do sprawdzania normalności reszt albo test Durbina-Watsona do analizy autokorelacji (ważne zwłaszcza przy danych czasowych). To wszystko pomaga nam upewnić się, że nasz model jest wiarygodny.
Jakie są potencjalne problemy i pułapki w stosowaniu regresji wielorakiej?
Używanie regresji wielorakiej może być trochę jak chodzenie po polu minowym. Jeśli nie będziemy uważać, możemy wpaść w pułapki, które doprowadzą nas do błędnych wniosków.
Multikolinearność i jej konsekwencje
Najczęstszy problem to multikolinearność, czyli sytuacja, gdy nasze zmienne X są ze sobą mocno powiązane. Wtedy trudno jest nam powiedzieć, która zmienna tak naprawdę wpływa na Y. Oszacowania współczynników stają się niestabilne, a ich błędy standardowe rosną. Sygnałem ostrzegawczym jest wysoki wskaźnik VIF (Variance Inflation Factor).
Wpływ niewystarczającej wielkości próby i przeuczenia modelu
Kolejny problem to za mała wielkość próby w stosunku do liczby zmiennych X. Wtedy wyniki mogą być przypadkowe i bardzo wrażliwe na pojedyncze obserwacje. Z drugiej strony mamy przeuczenie modelu (overfitting). Dzieje się tak, gdy model jest zbyt skomplikowany i zaczyna „uczyć się” szumu w danych, zamiast rzeczywistych zależności. Wtedy dobrze działa na danych, na których był trenowany, ale słabo przewiduje nowe.
Naruszenie założeń modelu i obserwacje odstające
Jeśli nasze dane mocno łamią podstawowe założenia (liniowość, normalność reszt, homoscedastyczność), to wyniki mogą być mylące. Obserwacje odstające (outliers) też potrafią mocno zniekształcić cały model. Dlatego tak ważne jest, żeby je wyłapywać i odpowiednio traktować – czasem trzeba je usunąć (jeśli mamy ku temu powody) lub zastosować transformacje danych.
Błędna interpretacja przyczynowości
Bardzo często mylimy korelację z przyczynowością. Regresja wieloraka pokazuje nam, jakie zmienne są powiązane i jak silnie, ale nie mówi nam, że jedna zmienna *powoduje* zmianę w drugiej. Zawsze trzeba pamiętać, że korelacja to nie przyczynowość.
Jakie są alternatywy dla regresji wielorakiej?
Czasem tak bywa, że klasyczna regresja wieloraka nie jest najlepszym rozwiązaniem. Dzieje się tak, gdy założenia modelu nie są spełnione albo gdy potrzebujemy czegoś bardziej elastycznego. Na szczęście jest sporo alternatywnych metod.
Kiedy rozważyć alternatywy?
Zastanów się nad innymi metodami, gdy:
- Zależności między zmiennymi są wyraźnie nieliniowe.
- Rozkład reszt mocno odbiega od normalnego.
- Multikolinearność jest bardzo silna i trudno ją rozwiązać.
- Analizujesz bardzo złożone dane i potrzebujesz bardziej zaawansowanych narzędzi.
Przegląd alternatywnych metod analizy
- Regresja nieparametryczna: Te metody nie zakładają z góry konkretnej formy zależności, co czyni je bardzo elastycznymi.
- Regresja regularyzowana (Ridge, Lasso): Świetne, gdy mamy do czynienia z silną multikolinearnością lub gdy liczba zmiennych X jest duża w porównaniu do liczby obserwacji. Pomagają zapobiegać przeuczeniu.
- Regresja nieliniowa: Stosowana, gdy zależność nie jest liniowa.
- Drzewa regresyjne i metody zespołowe (np. Random Forest): Potrafią modelować skomplikowane, nieliniowe zależności i interakcje między zmiennymi, często dając bardzo dobre wyniki predykcji.
- Sieci neuronowe: Bardzo zaawansowane modele, które potrafią wyłapać nawet bardzo subtelne i złożone wzorce w danych.
Pamiętaj, że wybór metody powinien być poprzedzony dokładną analizą danych i zrozumieniem, jak dana metoda działa.
Kiedy regresja wieloraka jest dobrym wyborem?
Regresja wieloraka to świetny wybór, gdy chcesz zrozumieć, jak wiele czynników jednocześnie wpływa na coś jednego i zakładasz, że te zależności są liniowe. To potężne narzędzie, ale pod warunkiem, że założenia modelu są w miarę spełnione, a dane odpowiednio przygotowane.
Najważniejsze jest, żeby zawsze sprawdzać te założenia i robić diagnostykę modelu. Analiza reszt, p-wartości dla współczynników i ogólne dopasowanie modelu (np. R²) pomogą Ci ocenić, czy Twój model jest wiarygodny. To często pierwszy i kluczowy krok w analizie wielu problemów badawczych i biznesowych.
Zachęcam Cię do tego, żebyś sam spróbował użyć regresji wielorakiej na swoich danych i zgłębiał tę tematykę. Tylko tak naprawdę wykorzystasz jej analityczny potencjał.
FAQ – najczęściej zadawane pytania o regresję wieloraką
Czym różni się regresja wieloraka od regresji prostej?
Regresja wieloraka analizuje wpływ wielu zmiennych niezależnych naraz na zmienną zależną. Regresja prosta skupia się tylko na jednej zmiennej niezależnej.
Czy regresja wieloraka zawsze wymaga liniowości?
Tak, podstawowa regresja wieloraka zakłada liniowe zależności. Jeśli chcesz modelować nieliniowości, możesz spróbować transformacji zmiennych albo użyć innych, nieliniowych metod regresji.
Jak duża musi być próba danych do regresji wielorakiej?
Ogólna zasada to co najmniej 10-20 obserwacji na każdą zmienną niezależną. Ale ile dokładnie danych potrzebujesz, zależy od wielu czynników, np. od złożoności problemu czy potrzebnej precyzji.
Czy współczynniki regresji wielorakiej oznaczają przyczynowość?
Absolutnie nie. Współczynniki pokazują siłę i kierunek związku (korelacji), ale nie dowodzą, że jedna zmienna powoduje zmianę w drugiej. Pamiętaj: korelacja to nie przyczynowość.
Kiedy powinienem rozważyć alternatywy dla regresji wielorakiej?
Rozważ inne metody, gdy widzisz wyraźne nieliniowości, gdy dane łamią założenie o normalności reszt, gdy jest silna multikolinearność albo gdy potrzebujesz bardziej elastycznych modeli do przewidywania złożonych zależności.


Poszukujesz agencji SEO w celu wypozycjonowania swojego serwisu? Skontaktujmy się!

Paweł Cengiel
Cechuję się holistycznym podejściem do SEO, tworzę i wdrażam kompleksowe strategie, które odpowiadają na konkretne potrzeby biznesowe. W pracy stawiam na SEO oparte na danych (Data-Driven SEO), jakość i odpowiedzialność. Największą satysfakcję daje mi dobrze wykonane zadanie i widoczny postęp – to jest mój „drive”.
Wykorzystuję narzędzia oparte na sztucznej inteligencji w procesie analizy, planowania i optymalizacji działań SEO. Z każdym dniem AI wspiera mnie w coraz większej liczbie wykonywanych czynności i tym samym zwiększa moją skuteczność.