
Pewnie zauważyłeś, że modele sztucznej inteligencji, takie jak Large Language Models (LLM), potrafią zdumiewająco dobrze pisać teksty, odpowiadać na pytania, czy tworzyć naprawdę kreatywne rzeczy. Ja też jestem pod wrażeniem ich możliwości! Ale wiesz, za tą całą „magiczną” fasadą kryje się coś, co trochę je ogranicza. Mówimy o Knowledge Cutoff, czyli „granicy wiedzy”. To taki moment w czasie, do którego model zna świat, a wszystko, co wydarzyło się później, jest dla niego wielką niewiadomą. Wiesz, zrozumienie tej kwestii to podstawa, jeśli chcesz używać AI w sposób mądry i odpowiedzialny, szczególnie w świecie, który zmienia się z dnia na dzień. Dlatego opowiem ci, czym dokładnie jest Knowledge Cutoff, jakie są jej konsekwencje dla aktualności AI, a co najważniejsze – przedstawię Ci sprawdzone sposoby, żeby sobie z tą granicą wiedzy poradzić, na przykład za pomocą Retrieval-Augmented Generation (RAG).
Co to jest Knowledge Cutoff w LLM? Definicja i podstawy
Knowledge Cutoff w LLM to konkretna data. Data, do której duży model językowy (LLM) „nauczył się” wszystkiego na podstawie danych, które mu podano. Zaraz wyjaśnię ci, jak w ogóle taką datę się ustala i dlaczego nie jest ona tym samym, co data stworzenia samego modelu.
Jaka jest precyzyjna definicja granicy wiedzy?
Wyobraź sobie, że Knowledge Cutoff to po prostu ustalona data – moment, do którego Large Language Model (LLM) zebrał swoją wiedzę z wszystkich materiałów treningowych. To oznacza, że model nie ma pojęcia o faktach, wydarzeniach czy informacjach, które pojawiły się po tym terminie. Chyba że ktoś go specjalnie zaktualizował. To tak, jakby ktoś zrobił „zdjęcie” internetu w konkretnym momencie i to właśnie ono stało się bazą wiedzy dla naszego modelu.
Jak ustalana jest data Knowledge Cutoff?
Data Knowledge Cutoff jest określana na podstawie tzw. Model Training Completion, czyli chwili, gdy model zakończył ostatni etap uczenia się na zewnętrznych danych, jeszcze zanim został oficjalnie wypuszczony w świat. Pamiętaj, to nie data, kiedy model powstał, ale data, do której „widział” świat w swoich danych treningowych. Twórcy modeli, jak na przykład OpenAI, otwarcie podają te daty. Na przykład, GPT-3.5 miał granicę wiedzy ustawioną na wrzesień 2021 roku, a Claude 2 na styczeń 2024 roku. W praktyce, ze względu na to, że dane różnie się starzeją i są inaczej przetwarzane, czasem pojawia się coś, co nazywamy „efektywnym cutoffem”. Może się okazać, że dla niektórych tematów ta data jest jeszcze wcześniejsza niż ta oficjalna.
Konsekwencje Knowledge Cutoff: dlaczego to problem?
Knowledge Cutoff to niestety spory problem dla funkcjonalności i wiarygodności Large Language Models (LLM), bo ta granica mocno określa to, co model wie. I to właśnie ona prowadzi do kilku nieprzyjemnych kłopotów, wpływających na to, czy modele potrafią podać ci aktualne i rzetelne informacje.
Dlaczego brakuje aktualnych informacji i wiedza jest statyczna?
Knowledge Cutoff powoduje, że modelowi brakuje bieżących informacji – co nazywamy Lack Of Current Information. No bo Large Language Models (LLM) mają wiedzę tylko do konkretnego dnia. One nie uczą się automatycznie nowych faktów ani nie odświeżają sobie bazy wiedzy po zakończeniu treningu. To sprawia, że ich wiedza jest Static Knowledge, czyli po prostu statyczna.A to? To może oznaczać, że model poda ci przestarzałe albo po prostu niepasujące informacje, szczególnie w dziedzinach, które szybko się zmieniają. Mam tu na myśli najnowsze wiadomości technologiczne, odkrycia naukowe czy choćby wydarzenia polityczne. Weźmy na przykład takie rzeczy:
- LLM nie będzie znał wyników ostatnich wyborów.
- Nie opowie ci o najnowszych osiągnięciach w dziedzinie sztucznej inteligencji.
- Nie ma pojęcia o wydarzeniach, które miały miejsce po jego dacie Knowledge Cutoff.
Dlaczego wiarygodność jest ograniczona i istnieje ryzyko „halucynacji”?
Problem Knowledge Cutoff wiąże się bezpośrednio z tym, że modele mają ograniczoną wiarygodność w kontekście najnowszych wydarzeń – to jest Limited Reliability For New Events. Kiedy poprosisz Large Language Model (LLM) o informacje na temat czegoś, co wydarzyło się po jego dacie granicznej, możesz dostać odpowiedzi, które są niepełne, niedokładne, a czasem wręcz całkowicie zmyślone. Takie zmyślone odpowiedzi nazywamy „halucynacjami” (Hallucinations (LLM)).
Wiesz, te „halucynacje” to spory kłopot, bo wymagają od ciebie, użytkownika, żebyś za każdym razem krytycznie weryfikował wszystkie informacje dotyczące bieżących wydarzeń. Pomyśl tylko, co by było, gdyby model „wymyślił” wyniki meczu, który odbył się po dacie jego treningu? No właśnie! Dlatego musisz sprawdzać fakty w innych, aktualnych źródłach.
Dlaczego wsparcie dla aplikacji działających w czasie rzeczywistym jest utrudnione?
Knowledge Cutoff bardzo utrudnia wspieranie aplikacji, które potrzebują informacji w czasie rzeczywistym. Large Language Models (LLM) cierpią na Lack Of New Market Information, czyli brakuje im danych o nowych produktach, usługach czy zjawiskach kulturowych. Modele nie uwzględniają innowacji rynkowych ani trendów społecznych, które pojawiły się po dacie ich treningu.
A przecież w dobie internetu informacje dezaktualizują się w zawrotnym tempie – to Information Obsolescence pod wpływem Internet Speed. Dane stają się przestarzałe w ciągu kilku dni, a nawet godzin. Brak dostępu do bieżących danych sprawia, że LLM-y po prostu nie nadają się do zadań, które wymagają śledzenia najświeższych zmian. Chyba że dostaną dodatkowe mechanizmy, które im w tym pomogą.
Metody aktualizacji wiedzy LLM po dacie Cutoff
Wiem, Knowledge Cutoff to jeden z najważniejszych problemów dla Large Language Models (LLM), ale na szczęście branża AI nie śpi! Rozwija szereg naprawdę skutecznych metod, żeby to ograniczenie pokonać i utrzymać modele na bieżąco z najnowszymi informacjami.
Retrieval-Augmented Generation (RAG) – genialne rozwiązanie!
Retrieval-Augmented Generation (RAG) to moim zdaniem najbardziej praktyczna i obecnie chyba najczęściej stosowana metoda na LLM aktualizacja wiedzy po dacie Knowledge Cutoff. Jak to działa? RAG łączy możliwości generowania tekstu przez Large Language Model (LLM) z elementem wyszukiwania. Ten element dynamicznie pobiera najnowsze informacje z zewnętrznych baz danych, dokumentów czy internetu. Dzięki temu model może tworzyć odpowiedzi, które nie tylko są spójne językowo, ale także aktualne i oparte na świeżych źródłach. I to wszystko bez konieczności ponownego, bardzo kosztownego trenowania całego modelu!
Wiesz, jak to działa?
- Ty zadajesz pytanie modelowi LLM.
- System RAG najpierw szuka najbardziej pasujących fragmentów informacji z zewnętrznej, na bieżąco aktualizowanej bazy danych.
- Te znalezione fragmenty trafiają do modelu LLM jako dodatkowy kontekst do twojego pytania.
- Model LLM generuje odpowiedź, wykorzystując zarówno to, co już wie, jak i ten nowy kontekst z zewnętrznych źródeł.
Zalety RAG? Jest ich sporo:
- Nie musisz ponosić kosztów i poświęcać czasu na ponowne trenowanie całego modelu.
- Bardzo łatwo i szybko zaktualizujesz bazę wiedzy, po prostu dodając nowe dokumenty.
- Możesz dopasować model do bardzo specyficznych dziedzin czy danych z konkretnej branży.
- Jest bardziej przejrzyście – często model potrafi nawet wskazać ci źródła, na których oparł swoją odpowiedź.
RAG zmienia zasady gry, bo pozwala nam wdrażać najbardziej zaawansowane modele językowe w dynamicznych środowiskach biznesowych, gdzie aktualność danych jest najważniejsza, a nie musimy przy tym ponosić gigantycznych kosztów ponownego trenowania.
Jakie są inne metody: Fine-tuning i prompt engineering?
Poza Retrieval-Augmented Generation (RAG), istnieją też inne sposoby na LLM aktualizacja wiedzy, choć często są droższe albo wymagają bardziej specyficznego zastosowania. Jedną z nich jest Fine-Tuning, czyli dobudowywanie lub dostrajanie już istniejącego modelu na nowych, mniejszych zbiorach danych. Jednak to dość kosztowna metoda pod względem obliczeniowym i czasochłonna, bo wymaga częściowego lub całkowitego ponownego trenowania modelu.
Inną techniką jest Prompt Engineering And Tool Integration. Polega to na bardzo precyzyjnym formułowaniu zapytań (czyli promptów) i integrowaniu Large Language Models (LLM) z zewnętrznymi narzędziami, takimi jak wyszukiwarki internetowe czy API baz danych. Dzięki temu model, pomimo swojej wewnętrznej Knowledge Cutoff, może aktywnie pobierać i wykorzystywać bieżące dane w czasie rzeczywistym. Takie podejście często fajnie uzupełnia i wzmacnia efektywność rozwiązań opartych na RAG.
Ewolucja i przyszłość Knowledge Cutoff w AI
Problem Knowledge Cutoff w Large Language Models (LLM) to nie jest coś stałego. On zmienia się i ewoluuje razem z postępem technologicznym i badaniami w dziedzinie sztucznej inteligencji. Twórcy modeli intensywnie szukają sposobów, żeby zmniejszyć wpływ tej granicy wiedzy na to, jak użyteczne i niezawodne są ich systemy.
Jak nowe generacje LLM radzą sobie z problemem?
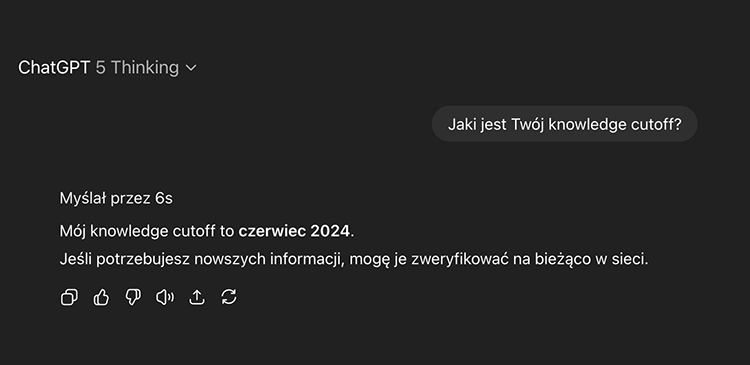
Nowe generacje Large Language Models (LLM) radzą sobie z problemem Knowledge Cutoff o wiele lepiej niż ich starsi bracia. Wczesne modele, takie jak GPT-3.5, miały wyraźną granicę wiedzy ustawioną na wrzesień 2021 roku. To często prowadziło do halucynacji AI albo błędnych odpowiedzi na pytania o bieżące wydarzenia. Współczesne modele, w tym GPT-4 i najnowszy GPT-4o, są znacznie częściej aktualizowane. Spójrz na to:
| Model | Knowledge Cutoff Date |
|---|---|
| GPT-4o | Czerwiec 2024 (po aktualizacji w styczniu 2025 – wcześniej listopad 2023) |
| GPT-5 | Czerwiec 2024 |
| DeepSeek V3 | Lipiec 2024 |
| Grok 3 i 4 | Listopad 2024 |
| Claude 4 | Styczeń 2025 |
| Gemini 2.5 Pro | Styczeń 2025 |
Ich Knowledge Cutoff stale się przesuwa, na przykład GPT-4o ma już czerwiec 2024 roku! Twórcy, tacy jak OpenAI, stawiają na większą transparentność. Nowsze modele nie tylko mają bardziej aktualną wiedzę, ale co super ważne – potrafią wyraźnie powiedzieć, kiedy zadane pytanie wykracza poza zakres ich danych treningowych, zamiast wymyślać jakieś bzdury. Ta zmiana na pewno buduje większe zaufanie użytkowników i pokazuje, że model ma świadomość swoich ograniczeń.
Jaka jest wizja przyszłości: AI, która uczy się w locie?
Wizja Future LLM Knowledge Management (czyli przyszłości zarządzania wiedzą w LLM) zakłada, że modele sztucznej inteligencji będą w stanie uczyć się i aktualizować wiedzę „w locie”. Bez potrzeby tego kosztownego i czasochłonnego pełnego retreningu. Eksperci, w tym Sam Altman, CEO OpenAI, przewidują, że Large Language Models (LLM) staną się samouczące. Będą umieć automatycznie odkrywać nowe informacje i od razu włączać je do swojej bazy wiedzy. To zmieni w zasadniczy sposób to, jak AI przetwarza i dostarcza dane, eliminując tradycyjną Knowledge Cutoff.
Podsumowanie
Wiesz, Knowledge Cutoff to taka podstawowa cecha Large Language Models (LLM), która określa, do jakiego momentu mają wbudowaną wiedzę z danych treningowych. Rozumienie tego ograniczenia jest naprawdę ważne, jeśli chcesz używać AI w sposób właściwy i odpowiedzialny. Choć ten problem wiąże się z konsekwencjami – jak brak aktualności informacji czy ryzyko halucynacji AI – na szczęście widzimy spory postęp. Dzieje się tak dzięki metodom takim jak Retrieval-Augmented Generation (RAG) i temu, że modele są częściej aktualizowane.
Mimo tych wszystkich usprawnień, twoja świadomość i krytyczne podejście do weryfikowania informacji są po prostu niezbędne. Przyszłość zapowiada, że systemy LLM aktualizacja wiedzy będą coraz lepsze, dążąc do AI, która uczy się na bieżąco. Zerknij czasem na naszą stronę, żeby nie przegapić najnowszych wiadomości i praktycznych porad dotyczących sztucznej inteligencji!
FAQ – najczęściej zadawane pytania o Knowledge Cutoff w LLM
Co to jest Knowledge Cutoff w kontekście modeli AI?
Knowledge Cutoff w kontekście modeli AI to konkretna data, do której Large Language Model (LLM) został wytrenowany na dostępnych danych. To oznacza, że model nie ma informacji o zdarzeniach, które wydarzyły się po tym terminie.
Dlaczego Knowledge Cutoff to problem dla dużych modeli językowych?
Knowledge Cutoff to problem, bo powoduje, że modelowi brakuje bieżących informacji (Lack Of Current Information), a jego wiedza jest statyczna (Static Knowledge). To zwiększa ryzyko „halucynacji” (Hallucinations (LLM)), kiedy model próbowałby odpowiedzieć na pytania o wydarzenia, które miały miejsce po dacie jego treningu.
Czy modele LLM mogą uzyskiwać dostęp do informacji w czasie rzeczywistym?
Same Large Language Models (LLM) nie potrafią uzyskiwać dostępu do informacji w czasie rzeczywistym po dacie Knowledge Cutoff. Ale wiesz, można je zintegrować z zewnętrznymi narzędziami, takimi jak wyszukiwarki internetowe czy bazy danych, na przykład za pomocą metod typu Retrieval-Augmented Generation (RAG). Wtedy mogą dynamicznie pobierać aktualne dane.
Co to jest RAG i jak pomaga w problemie granicy wiedzy?
Retrieval-Augmented Generation (RAG) to technika, która łączy generowanie tekstu przez LLM z mechanizmem wyszukiwania. Ten mechanizm pobiera aktualne informacje z zewnętrznych źródeł, co pozwala modelom uwzględniać najnowsze dane i skutecznie radzić sobie z ich wewnętrzną Knowledge Cutoff.
Czy AI kiedykolwiek całkowicie pokona problem Knowledge Cutoff?
Eksperci, jak na przykład Sam Altman, przewidują, że Future LLM Knowledge Management będzie dążyć do stworzenia AI, która będzie zdolna do samouczenia się i ciągłego aktualizowania wiedzy. To ma w dużej mierze przezwyciężyć problem Knowledge Cutoff, ale pamiętaj, to wciąż obszar bardzo intensywnych badań.


Poszukujesz agencji SEO w celu wypozycjonowania swojego serwisu? Skontaktujmy się!

Paweł Cengiel
Cechuję się holistycznym podejściem do SEO, tworzę i wdrażam kompleksowe strategie, które odpowiadają na konkretne potrzeby biznesowe. W pracy stawiam na SEO oparte na danych (Data-Driven SEO), jakość i odpowiedzialność. Największą satysfakcję daje mi dobrze wykonane zadanie i widoczny postęp – to jest mój „drive”.
Wykorzystuję narzędzia oparte na sztucznej inteligencji w procesie analizy, planowania i optymalizacji działań SEO. Z każdym dniem AI wspiera mnie w coraz większej liczbie wykonywanych czynności i tym samym zwiększa moją skuteczność.





